Navigation
- Awesome GEMM: A Curated List of GEMM Frameworks, Libraries and Software
- LightNeuron: An Educational Inference Framework
- Stanford CS149: Parallel Computing
- Insight Mastodon: NLP Analysis with Spark
- Hands-on SIMD Programming with C++: A Practical Guide
- LZ77 Compression: A C Implementation
- LeakCheck: A Memory Leak Detector (MLD) for C
- Eva: A Functional Programming Language
- Algo Playground: A Collection of DS/A Implementations in Python/Java
Awesome GEMM: A Curated List of GEMM Frameworks, Libraries and Software
Keywords: Matrix Multiplication, High-Performance Computing, Numerical Analysis, Software Optimization, Computational Efficiency.
Awesome GEMM is a curated list of awesome matrix-matrix multiplication (A * B = C) frameworks, libraries and software. It serves as a comprehensive resource for developers and researchers interested in high-performance computing, numerical analysis, and optimization of matrix operations.

LightNeuron: An Educational Inference Framework
Keywords: Neural Networks, GEMM Optimization, x86-64 Architecture, C Programming, CPU Efficiency.
LightNeuron is a highly efficient, educational neural network library designed for x86-64 architectures in C. It aims to provide insights into neural network mechanics, profiling, and optimization, with a special focus on the efficiency of General Matrix Multiply (GEMM) operations.
Targeted primarily at students, researchers, and developers, LightNeuron offers a CNN inference framework capable of processing HDF5 model files. This facilitates the integration with models trained on frameworks like PyTorch and TensorFlow. Key features include:
- Convolutional Layer Computation (conv())
- Matrix Multiplication (matmul())
- Activation Functions (relu())
- Pooling (pooling())
- Forward Pass Operations (forwardPass())
- Feature Extraction and Interpretation
- Prediction (softmax(), predict())
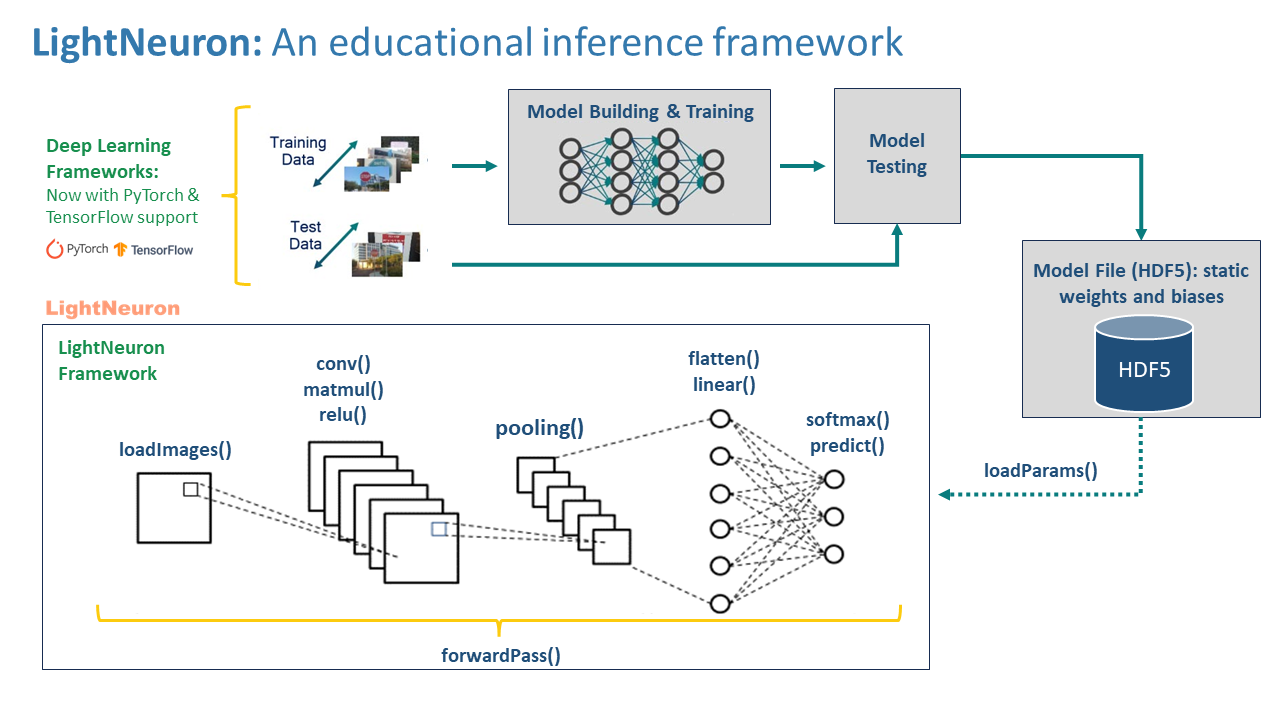
Figure: LightNeuron CNN Inference Framework.
LightNeuron places a strong emphasis on optimizing General Matrix Multiply (GEMM) operations. This optimization leads to significant performance improvements, as measured in GFLOPS (Giga Floating Point Operations Per Second), particularly noticeable across a range of matrix dimensions. Key strategies employed in this optimization include:
- Intricate Loop Unrolling: Enhances computational efficiency by reducing loop overhead.
- Proactive Data Prefetching: Improves data access speeds from memory.
- Strategic Cache Management: Optimizes the use of CPU cache to minimize data retrieval delays.
- Precise Data Alignment: Ensures data is appropriately aligned in memory, reducing access times.
- Concurrent Multithreading: Leverages parallel processing capabilities of modern CPUs.
- Specialized Instruction Sets Utilization: Takes advantage of x86 architecture-specific features like AVX2 and SSE to accelerate computations.
The result of these enhancements is a notable increase in CPU computational efficiency, boosting the performance of matrix multiplication operations considerably.
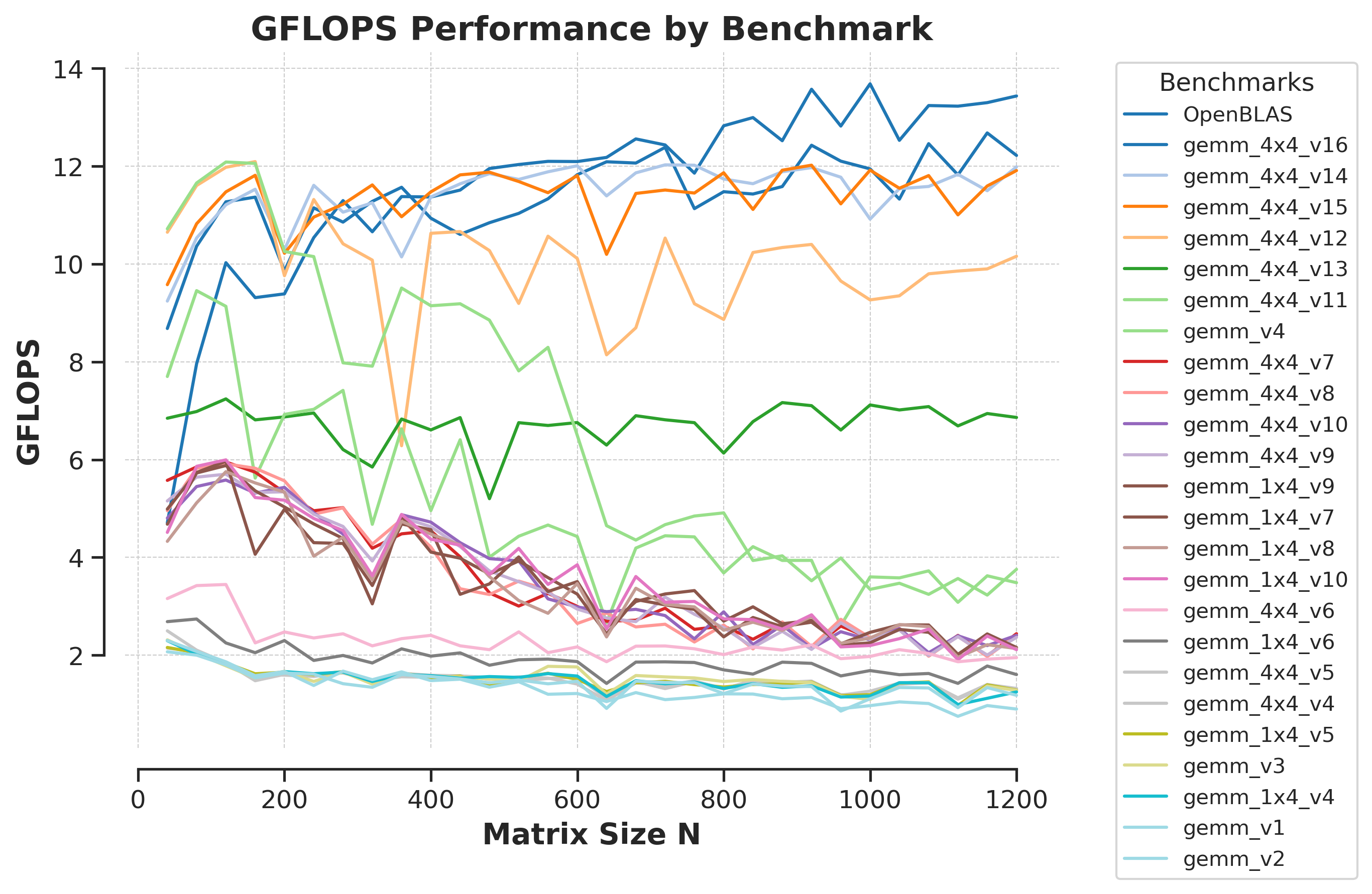
Figure: Performance of matrix multiplication operations in LightNeuron, measured in GFLOPS.
Stanford CS149: Parallel Computing
Keywords: Parallel Computing, Performance Analysis, SIMD, OpenMP, CUDA Programming.
Stanford CS149 aims to impart a fundamental grasp of the principles and trade-offs in modern parallel computing system design. It also focuses on teaching parallel programming skills necessary to effectively leverage these systems. An integral part of the course is understanding machine performance characteristics, hence both parallel hardware and software design are covered.
This repository contains my solutions to the programming assignments for CS149, which include:
- Analyzing Parallel Program Performance on a Quad-Core CPU
- Scheduling Task Graphs
- Big Graph Processing in OpenMP
Insight Mastodon: NLP Analysis with Spark
Keywords: Distributed Computing, Natural Language Processing, Apache Spark, Network Analysis, Big Data.
Insight Mastodon implements a robust data pipeline for analyzing Mastodon toots, utilizing Apache Spark (with PySpark for Python integration) and Apache Hadoop. Designed for local and cloud (AWS Lambda) environments, it leverages Docker for seamless operation.
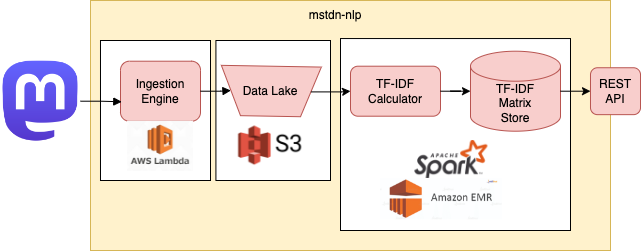
Figure: Architecture of the Mastodon toot analysis pipeline.
Hands-on SIMD Programming with C++: A Practical Guide
Keywords: Performance Engineering, SIMD Programming, C++ Programming, Parallel Processing, Instruction Sets.
Hands-on SIMD Programming with C++ provides a practical, step-by-step guide to SIMD (Single Instruction, Multiple Data) programming in C++, tailored for beginners. Through a progressive, example-driven approach, it delves into the fundamental techniques of SIMD programming, emphasizing minimal code to cover a broad range of methods. The guide ensures a smooth learning curve for SIMD programming noobs.
LZ77 Compression: A C Implementation
Keywords: Data Compression, LZ77, Sliding Window, C Programming.
A C implementation of the LZ77 compression algorithm, featuring a sliding window and a look-ahead buffer.
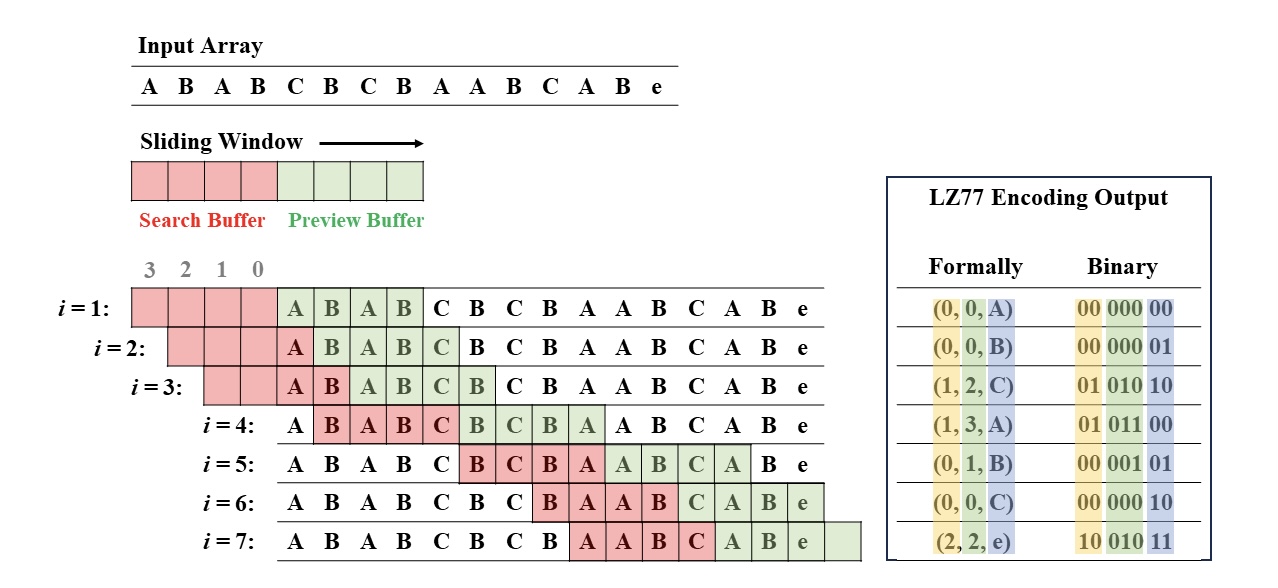
Figure: LZ77 is a lossless data compression algorithm that encodes data by referencing earlier occurrences of the same data within a sliding window.
LeakCheck: A Memory Leak Detector (MLD) for C
Keywords: Memory Leak Detection, C Programming, Directed Cyclic Graphs, Software Reliability, Automated Analysis.
LeakCheck is a dedicated memory leak detection library designed for C applications. It provides an automated approach to identify memory leaks that can often go undetected, thereby improving the performance and reliability of applications.
Key Features:
- Directed Cyclic Graph (DCG): Utilizes DCGs for a clear representation of memory allocations, where nodes signify allocated objects, and edges represent pointers.
- Depth-First Search (DFS) Algorithm: Employs DFS to deeply navigate the object graph, detecting unreachable objects indicative of memory leaks.
- Linked-List Based Struct and Object DBs: Implements struct and object databases using linked lists for efficient tracking and management of memory allocations.
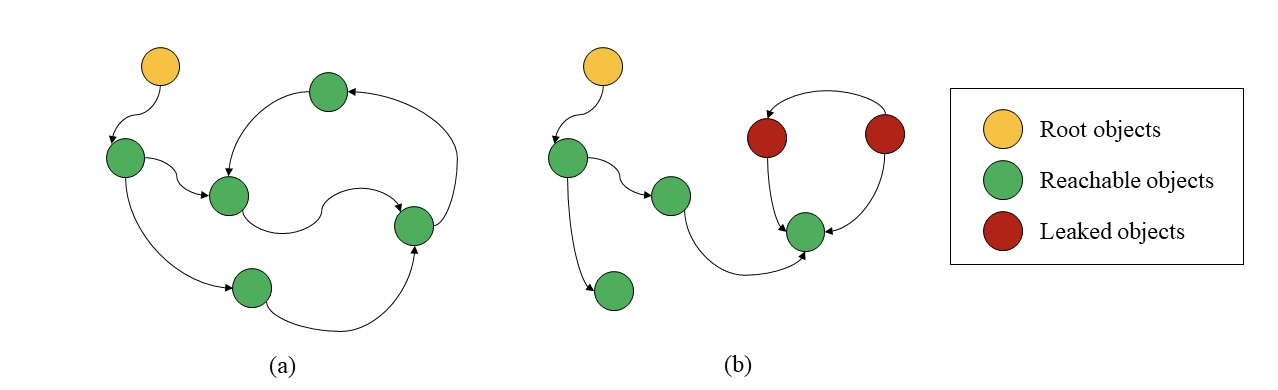
Figure: Visualization of memory allocation state using Directed Cyclic Graphs (DCG) in LeakCheck, depicting (a) an ideal scenario without any leaked objects, and (b) a scenario with detected memory leaks.
Eva: A Functional Programming Language
Keywords: Functional Programming, Language Design, Interpreter Workflow, Syntax Analysis, Lexical Scoping.
Eva is a modern functional programming language designed to offer an intuitive and powerful approach to software development. It seamlessly integrates core concepts of functional programming with the versatility of object-oriented paradigms.
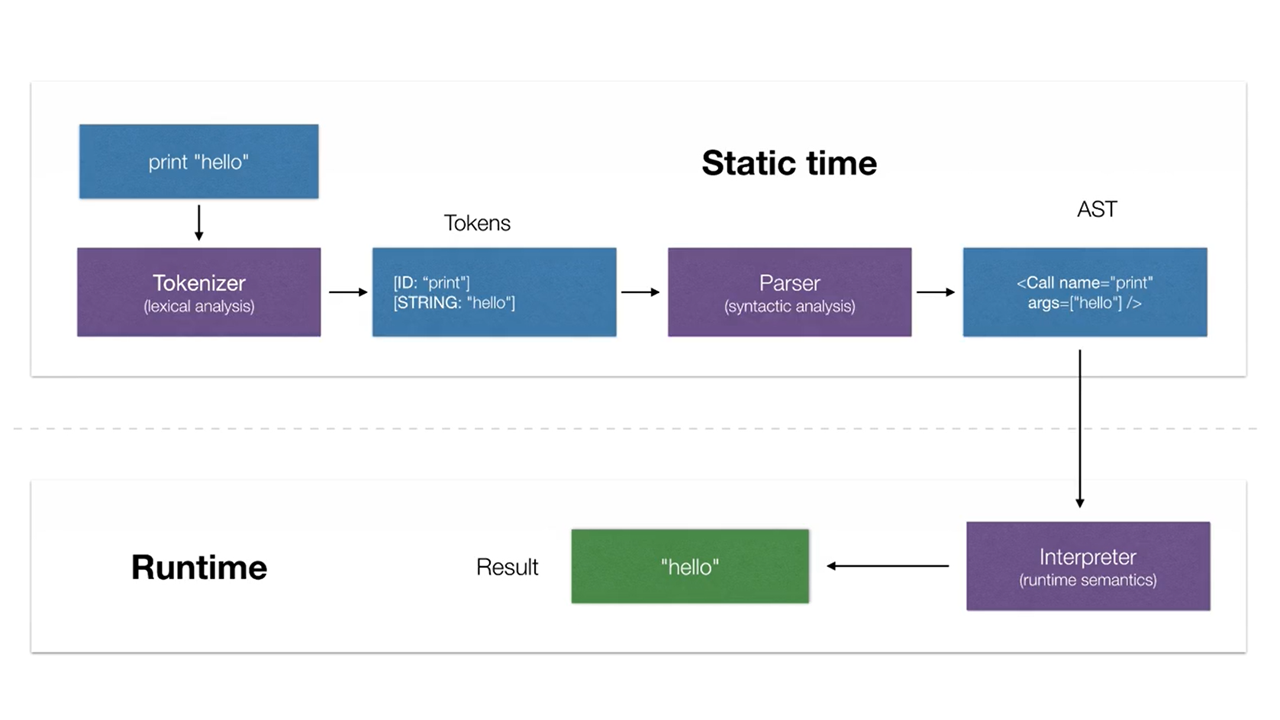
Figure: Interpreter Workflow Diagram - Depicting the lexing, parsing, and interpretation phases, this figure outlines the transformation from source code to executable output in the Eva language interpreter.
Features
Expressions & Variables: Eva handles basic expressions and variables with a focus on scopes and lexical environments. It features robust control structures and employs a parser generator for syntax analysis.
Functional Programming: The language supports function abstraction and invocation with an emphasis on closures, lambda functions, and IILEs (Immediately-invoked Lambda Expressions). It also includes a well-defined call-stack, supports recursion, and provides syntactic sugar for enhanced readability.
Object-Oriented Programming: Eva extends its functionality to object-oriented concepts, offering both class-based and prototype-based paradigms. It allows developers to define classes, create instances, and organize code into modules for better modularity.
Algo Playground: A Collection of DS/A Implementations in Python/Java
Keywords: Data Structures, Algorithms.
Algo Playground is a collection of algorithms and data structures implemented in Python and Java, featuring trees, graphs, stacks, linked lists as well as algorithms such as DFS and BFS. It serves as a playground for refining my skills in algorithmic design and data structure optimization.